Message boards : Number crunching : Error code 22 / Missing Data In Ocean UV Field
Message board moderation
Previous · 1 · 2
| Author | Message |
|---|---|
 geophi geophiSend message Joined: 7 Aug 04 Posts: 2187 Credit: 64,822,615 RAC: 5,275 |
I\'ve had two models crash with missing date in ocean uv field errors. One in April when the work unit was created with an April 11th date (Exit code 22, model got to 1936 before crashing) and another back in March where the work unit was created with a December 11th date (Exit code 0, got to 2045 before crashing). Edit...No backup of either one. |
|
mo.v Send message Joined: 29 Sep 04 Posts: 2363 Credit: 14,611,758 RAC: 0 |
TylerChris said in the first post of this thread that he had a backup of his 22 code model. Whether he still has it is another question. If nobody posts in the next day or two to say they have a pre-22 backup, I\'ll see if I can get in touch with him. Cpdn news |
|
Send message Joined: 14 Jan 07 Posts: 52 Credit: 284,001 RAC: 0 |
Yes it is still snoring gently in \'My Docs\' Just opened it up,it was taken on 25-02-42,the crash happened about 01 Dec 56. It would take a week of 24/7 crunching to get it back to the crash date,feel pretty sure it would crash again at the same point.The result is Here. Chris.   |
|
mo.v Send message Joined: 29 Sep 04 Posts: 2363 Credit: 14,611,758 RAC: 0 |
Chris, could you please register on the independent forum (I couldn\'t find your name as TylerChris in the memberlist) so the programmers in Oxford can contact you by private message if they need to. Thanks. http://www.climateprediction.net/board/index.php Cpdn news |
|
Send message Joined: 6 Apr 05 Posts: 17 Credit: 744,057 RAC: 0 |
I had a model crash with this error after 5,800,000 CPU seconds on an AMD X2 5600+. That\'s over two months of running 24x7, and over 80% completed. Very aggravating. --Mike |
|
Iain Inglis Send message Joined: 9 Jan 07 Posts: 467 Credit: 14,549,176 RAC: 317 |
I had a model crash with this error after 5,800,000 CPU seconds on an AMD X2 5600+. That\'s over two months of running 24x7, and over 80% completed. The list of error/warning messages for that model contains the text \"NEGATIVE THETA DETECTED\" towards the end. Unless this is spurious for some reason, this message is normally taken to mean that the model had become unphysical and could not continue. I\'ve had a few myself, and they are rather annoying ... What is, perhaps, rather odd is to get that message in a control run (look for ghg_cntrl in the parameters). Best of luck with the others. |
|
MikeMarsUK Send message Joined: 13 Jan 06 Posts: 1498 Credit: 15,613,038 RAC: 0 |
I\'ve also replied against the other (identical) post, and suggested running Prime95\'s torture test on the PC. I'm a volunteer and my views are my own. News and Announcements and FAQ |
|
Send message Joined: 6 Apr 05 Posts: 17 Credit: 744,057 RAC: 0 |
MikeMarsUK, I took your advice and ran two instances of Prime95 on my dual core. I found that one core doesn\'t mind overclocking, the other one does. So I\'ve ceased overclocking altogether, since I don\'t see any upside. Since then, I\'ve run Prime95 overnight two additional times and they ran clean. Two weeks into the next WU, it crashed with \"missing data in ocean UV field\" which sounds to me more like model instability than machine instability. Thoughts? --Mike |
|
Iain Inglis Send message Joined: 9 Jan 07 Posts: 467 Credit: 14,549,176 RAC: 317 |
It\'s sometimes possible for a model to survive an isolated \"missing data in ocean UV field\", but your model has six in a row (presumably rewinding and retrying). If you have a backup, then you could give that a go. Otherwise, you\'re probably right - that model was not going to finish. |
|
Send message Joined: 11 Dec 05 Posts: 6 Credit: 1,468,014 RAC: 0 |
http://climateapps2.oucs.ox.ac.uk/cpdnboinc/result.php?resultid=6910804 I just had the same problem on a WU that managed to get from 2000 to 2065. No problems with the machine - it is a production webserver! I take daily backups using rsync, but I don\'t think it is worth restoring because it\'ll probably just do the same thing again, and the machine has also just downloaded a new WU. Better to make sure that all the models have all the data they will need during their lifespans! Curiously, the deadlines for that one and the new job is backdated to 2002, surely a mistake? I think the validator ignores missed deadlines because the data is too valuable to just throw away, but backdating WUs in this way pushes BOINC into EDF mode. It isn\'t a real problem, but perhaps it should be looked at to avoid more chatter! Cheers, Andy. |
|
Iain Inglis Send message Joined: 9 Jan 07 Posts: 467 Credit: 14,549,176 RAC: 317 |
... Better to make sure that all the models have all the data they will need during their lifespans! ... Andy, Your inference from the error message is quite sensible, but the message doesn\'t quite mean what it appears to say. The message relates to a failure to transfer data from the ocean to the atmosphere (U and V refer to grids, not ultra-violet!). As I understand it, the error message is really about computation rather than the availability of input data. No-one in that work unit made it anything like as far as you did. My expectation would be that no-one would have got any further on the same platform. Iain |
|
mo.v Send message Joined: 29 Sep 04 Posts: 2363 Credit: 14,611,758 RAC: 0 |
Andy, the deadline for your new model says 2012 on your computer\'s results page: http://climateapps2.oucs.ox.ac.uk/cpdnboinc/results.php?hostid=551091 Could you please tell us again what the deadline says in the Tasks window of BOINC manager? (We know there\'s a problem about deadlines of some new models.) Cpdn news |
|
Send message Joined: 11 Dec 05 Posts: 6 Credit: 1,468,014 RAC: 0 |
Andy, the deadline for your new model says 2012 on your computer\'s results page: Ah, thanks for the pointer - yes, looks fine there... Here is my CPDN task list as shown via BoincView via an ssh tunnel to the webserver running Crunch3r\'s client 5.5. 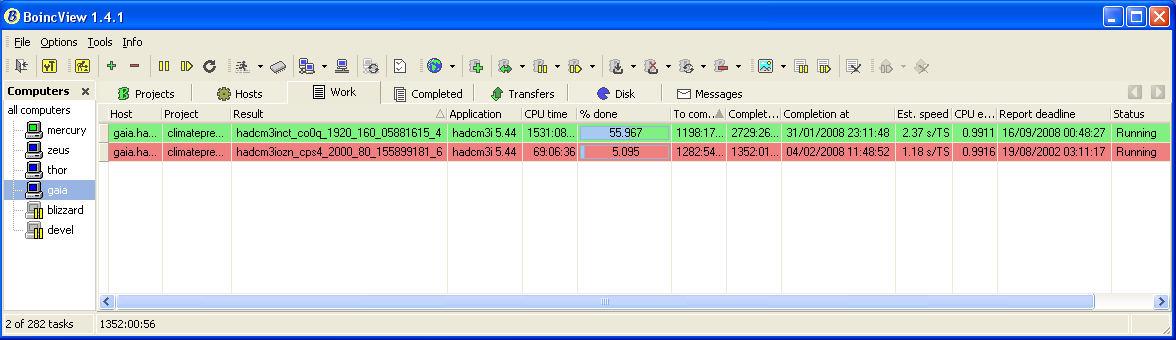 The task is highlighted in red because it thinks it has expired, and note also the erroneous 1.18 s/TS - the machine is a 4200+, not an overclocked Core2! These errors could arise from the workunit, client or boincview and therefore probably not so easy to identify. Having said that, the other task looks to be reporting OK even though it is a particularly demanding one. Cheers, Andy. |
|
mo.v Send message Joined: 29 Sep 04 Posts: 2363 Credit: 14,611,758 RAC: 0 |
Thanks for the pic which does help. Tolu recently lengthened the deadline for HADCM models because of the constant complaints about how these long models were treated by the BOINC scheduler when running on the same computer as short WUs from other projects. He seems to have made the deadline 2012 for both 80 and 160-year models. I\'m not sure whether this is what Tolu really intended to do! He will have to change this again, probably still keeping the deadlines longer than they originally were, because Thyme Lawn has discovered that BOINC can\'t handle deadlines longer than 1000 days. Other members with a 2012 deadline were having it reset by BOINC to 1901. That\'s why I thought your mention of 2002 was a typo. I assume that your models are running on Crunch3r\'s BOINC version? This version obviously can\'t handle the overlong deadline either, but seems to have reset it differently, to 2002 instead of 1901. As these seem to be the only tasks running on this computer, you can simply let the models crunch on. The deadline in the past is only a problem vis-à-vis the task scheduler and shouldn\'t affect the stability of the model. It would be pointless to download extra short WUs from other projects as the scheduler would not like the situation. By the time you download a new CPDN model, Tolu should have resolved the deadline problem and you\'d be able to run short WUs alongside on the same computer. Cpdn news |
|
Send message Joined: 11 Dec 05 Posts: 6 Credit: 1,468,014 RAC: 0 |
I think anyone taking on these tasks should be committed to seeing them through, and dedicate whole machines to them. 1000 day limit? I hate arbitrary limits because they will always bite someone somewhere! M$ is famous for that crime! Yes, I don\'t anticipate having a \'wrong\' deadline will cause any problems. The machine is dedicated and CPDN runs completely unobtrusively so can largely forget it\'s even there. Hopefully this thread will help others with similar questions. Cheers, Andy. |
|
Send message Joined: 5 Sep 04 Posts: 7629 Credit: 24,240,330 RAC: 0 |
1000 days isn\'t really a worry, because any work unit which takes nearly 3 years to complete will most likely be obsolete by then. |
|
mo.v Send message Joined: 29 Sep 04 Posts: 2363 Credit: 14,611,758 RAC: 0 |
For multiproject crunchers with more than one computer, reserving a whole machine/s for CPDN is definitely the best solution. There have to be limits to prevent a computer forgotten but left on from crunching indefinitely. The WUs also have a CPU time limit incorporated. In the case of CPDN this is an essential feature as some models have turned out to be indefinite loopers; they have to be cut short at some point. Cpdn news |
|
Thyme Lawn Send message Joined: 5 Aug 04 Posts: 1283 Credit: 15,824,334 RAC: 0 |
He will have to change this again, probably still keeping the deadlines longer than they originally were, because Thyme Lawn has discovered that BOINC can\'t handle deadlines longer than 1000 days. Other members with a 2012 deadline were having it reset by BOINC to 1901. That\'s why I thought your mention of 2002 was a typo. The deadline reset only happens with BOINC versions earlier than 5.8.16. Crunch3r\'s version 5.5 client will be using the broken code. "The ultimate test of a moral society is the kind of world that it leaves to its children." - Dietrich Bonhoeffer |

©2024 cpdn.org