Message boards :
Number crunching :
How to optimize credit production with OpenIFS tasks
Message board moderation
| Author | Message |
|---|---|
|
Send message Joined: 29 Oct 17 Posts: 1048 Credit: 16,404,330 RAC: 16,403 |
The graph below shows tests on one of my PCs. The blue line is the rate at which it's producing credit (equivalent to how many tasks per day completed). The grey bars indicate the wall-clock runtime for a single task. As the number of running tasks is increased, the task runtime goes up until I can't do any better at completing tasks faster when I get to running 6 tasks i.e. the same number of cores (not threads) on the machine. If I run more tasks than 6 the blue line heads down leading to a lower credit production. Best to not run more OpenIFS tasks than you have cores, even if you have the memory. I usually run 1 less than # cores if I'm also using the machine for something else. There were no other boinc projects running. I would imagine this to be generally true though chips with extra memory channels or DDR5 might give slightly different results. OpenIFS needs much more memory to run than the current Hadley models and other typical boinc project. The model also moves alot of memory around so memory bandwidth and contention is a limiting factor with this model.  OpenIFS credit production graph.. OpenIFS credit production graph..The tests used a i5-12400F, 6 cores / 12 threads with 128Gb DDR4-3000. To run the tests, I started up all 10 tasks on the machine and left them running for 20 mins to let model & cpu temps settle. From 1 task, I took a reading of percentage done from boincmgr and noted the clock time, waited 15mins and took percentage from same task & time. From that, can work out total clock time for a completed task, divide into 24hrs & multiply by # of running tasks to get tasks completed/day. Then suspend one of the tasks (make sure nothing else starts), and repeat. Also worth noting a 5degC CPU temp difference between running 10 & 6 tasks. Just an aside but I was pleasantly surprised with the Intel stock cooler on this machine (haven't yet got around to installing the tower cooler). The stock cooler managed to keep the temp to just over 70C (but then it is cold here!). |
|
Send message Joined: 1 Jan 07 Posts: 1061 Credit: 36,690,861 RAC: 10,559 |
I think that graph very clearly demonstrates the strengths and weaknesses of hyperthreading technology, on a machine primarily dedicated to CPU-intensive BOINC crunching. Hyperthreading works by trying to do two things at once on the same CPU core, by minimising the time spent switching from one to the other. This works well if the two 'things' are different, and utilise different parts of the core's silicon composition. It'll probably be beneficial if you're doing some word processing or web browsing at the the same time as predicting the climate. But if both threads are asked to do the same thing - especially if it's floating point compute-intensive - there's no spare silicon left: only one task can really make use of the FPU and SIMD processor at a time. So the other one has to wait. By the time you get up to 10 threads, you're doing almost exactly twice the work in twice the time, with no efficiency gain at all. But you probably are driving other components of the computer harder: the memory controller, RAM chips, and their respective cooling systems. I'd agree with Glenn - if you're concentrating on one BOINC project at a time, it's probably not worth using hyperthreading at all. There might be something to be gained when running a mixture of dissimilar projects, but it would be worth carrying out a similar experiment on your own hardware first. |
|
Send message Joined: 27 Mar 21 Posts: 79 Credit: 78,302,757 RAC: 1,077 |
if you're concentrating on one BOINC project at a time, it's probably not worth using hyperthreading at all.This is not universally true. Quite often there are gains,¹ at least with Haswell and later and even more so with Zen and later. ________ ¹) WRT host throughput. Task energy is another question. |
|
Send message Joined: 5 Aug 04 Posts: 1120 Credit: 17,202,915 RAC: 2,154 |
if you're concentrating on one BOINC project at a time, it's probably not worth using hyperthreading at all. It seems to me that if the instruction cache on your machine is large enough to contain the entire working set of instructions, you could get a very high hit rate for the instructions by running them at the same time. (With something like Oifs, this would probably not work at all, but with "classical" CPDN tasks, I would think a lot of benefit could be had.) Nothing would help much with the data cache of course. 
|
|
Send message Joined: 7 Sep 16 Posts: 262 Credit: 34,915,412 RAC: 16,463 |
It seems to me that if the instruction cache on your machine is large enough to contain the entire working set of instructions, you could get a very high hit rate for the instructions by running them at the same time. I tend to track "instructions retired per second" when handwavingly optimizing ("BOINCtimizing") my machines, and I've noticed this effect. If I run all the same task, I get quite a few more instructions per second retired than if I have a mix, and I believe the fact that the I-cache isn't thrashing has a lot to do with it. I'm actually surprised that there isn't a regression in tasks per day. I've seen, more than a few times, running 24 threads vs 12 or 18 threads, actually reduce the total instructions per second retired on my 3900Xs - again, cache thrashing is almost certainly the culprit. Just, data cache or L2/L3 cache, this time. |
|
Send message Joined: 29 Oct 17 Posts: 1048 Credit: 16,404,330 RAC: 16,403 |
This article has an interesting discussion about codes, including weather models, running on HPC machines and what kind of hardware is desirable. (Open)IFS was designed from the ground-up for HPC and ECMWF provide it as a benchmark model for HPC vendors. More CPU Cores Isn’t Always Better, Especially In HPC https://www.nextplatform.com/2023/01/19/more-cpu-cores-isnt-always-better-especially-in-hpc/ |
|
Send message Joined: 14 Sep 08 Posts: 127 Credit: 41,541,636 RAC: 58,436 |
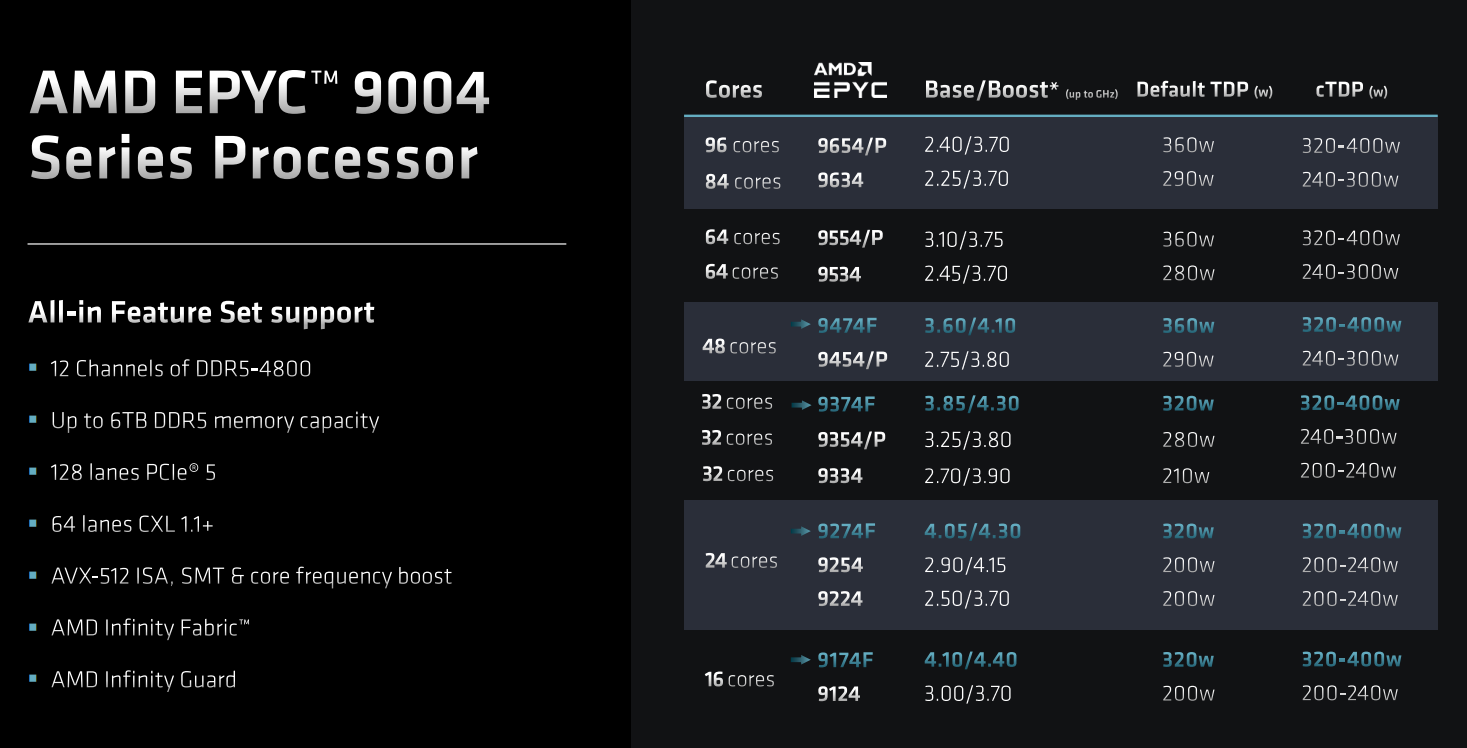
This article has an interesting discussion about codes, including weather models, running on HPC machines and what kind of hardware is desirable. (Open)IFS was designed from the ground-up for HPC and ECMWF provide it as a benchmark model for HPC vendors. The article is generally reasonable, but seems to have misunderstood the server market line-ups provided by both vendors. 1. Those high core count SKUs were not for HPC at first place. For scale-out workload that Bergamo is targeting, higher core count is the king. There are separate high frequency lower core count parts designed for HPC that still provides full memory size and bandwidth. AMD makes it clear in marketing material, though you likely have to sort through Intel's SKU list to find the right parts and hope they didn't gut the memory capability for lower core count ones. Specifically, for this “It’d be much nicer to have an 8 core or 16-core part at a 4-plus GHz kind of frequency”. On AMD side, parts with F suffix directly tackle this market. This has been the case since Zen 2 and Genoa is no exception. Those 9*74F are meant for this. Intel has similar offerings. 2. On bandwidth side, it's a universal pain shared by not only HPC, but all workloads, including the scale-out ones our company mostly runs. Whatever you see, whether it's HBM or DDR5 on top parts are the max configuration manufacturing can achieve for now. Everyone is asking for more memory bandwidth since we've hit the bandwidth wall, but we are all limited by physics. CXL memory is the answer industry is pursing, but we likely need another generation or two for CXL3 ecosystem to mature. I suspect HPC applications that are no stranger to NUMA could easily reap the benefit. In a few years, we probably would end up having SRAM (L1/L2/L3) -> HBM -> DDR -> DDR on CXL. Each step going down the hierarchy would likely be an order of magnitude of more capacity at the expense of almost doubling latency. |

©2024 cpdn.org
{kind=link}
{kind=link}